Production-Grade AI Inference with KServe, llm-d, and vLLM: A Red Hat and Tesla Success Story
· 5 min read




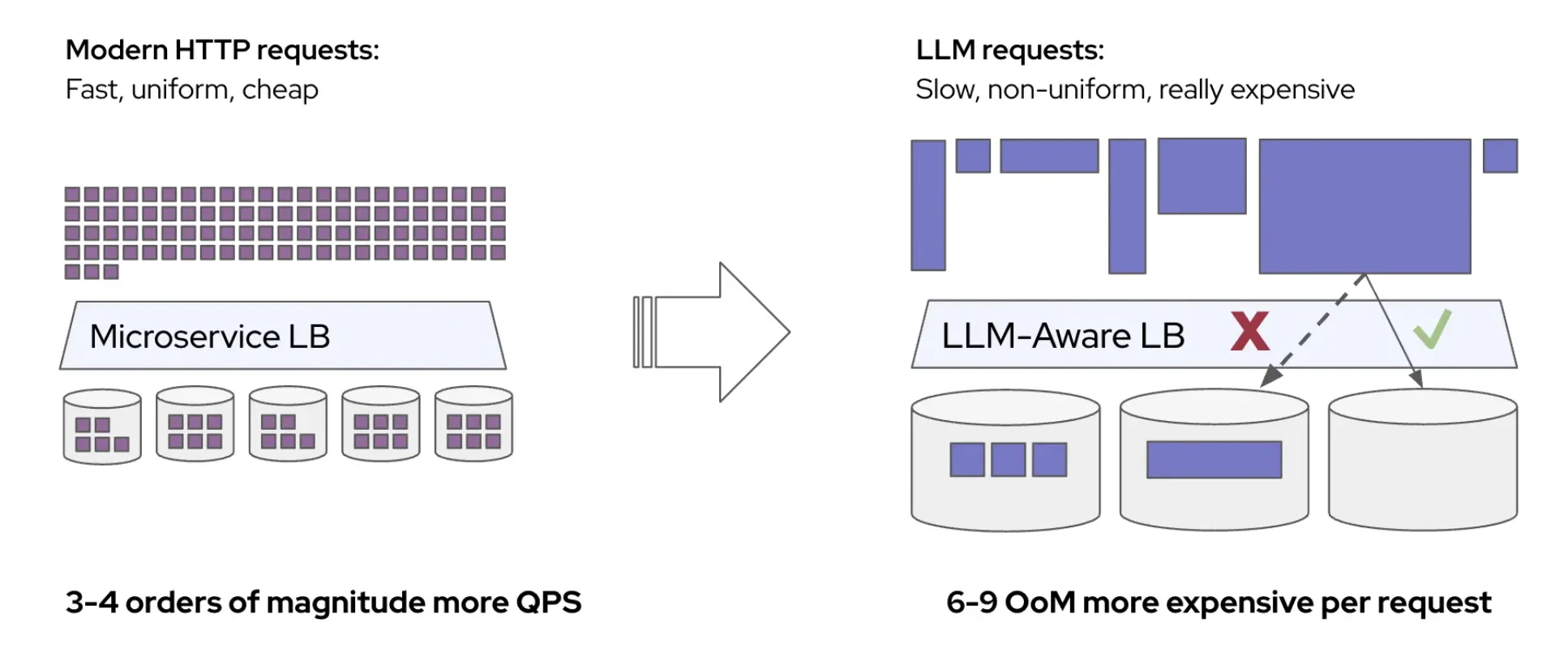
The Problem with "Simple" LLM Deployments
Everyone is racing to run Large Language Models (LLMs), in the cloud, on-prem, and even on edge devices. The real challenge, however, isn't the first deployment; it's scaling, managing, and maintaining hundreds of LLMs efficiently. We initially approached this challenge with a straightforward vLLM deployment wrapped in a Kubernetes StatefulSet.